Les Travaux de Fin d'Études en IG
2018-2019

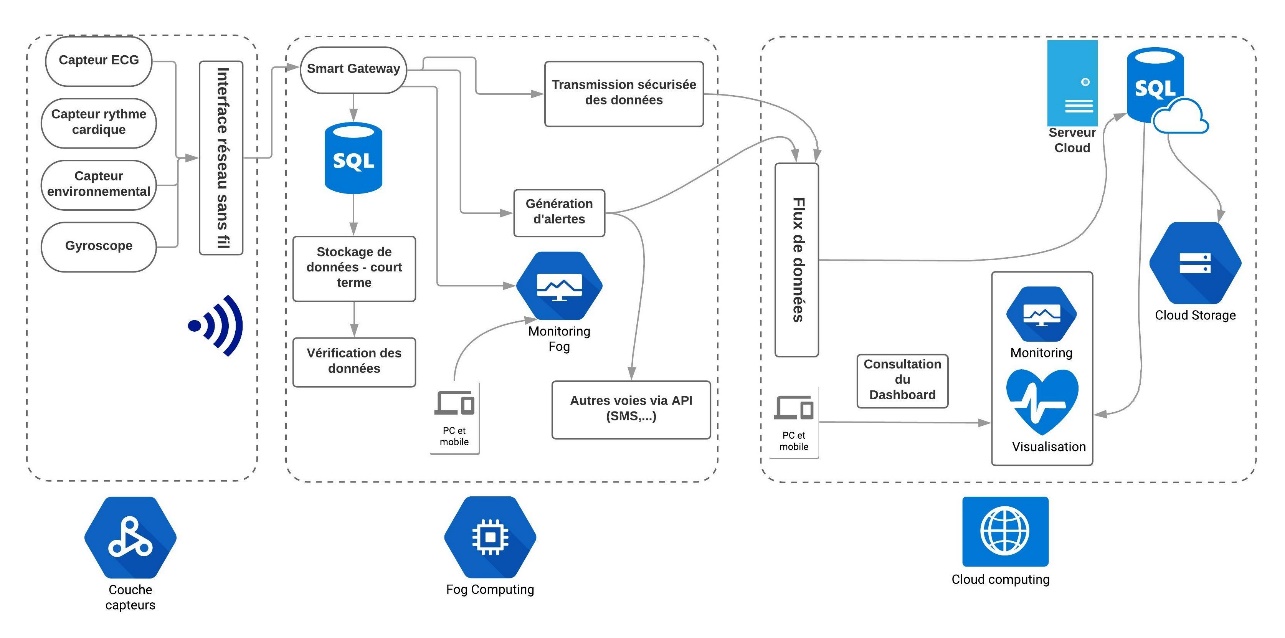
Conception et développement d’une plateforme d’objets connectés dédiée à la santé
Travail réalisé par : Abdessamad ASSILA – 2019
L’objectif de ce travail est de développer une plateforme de stockage et de traitement en temps réel des données médicales provenant de capteurs connectés, et transmises au Cloud grâce à un réseau télématique spécifique à l’Internet des Objets.
L’architecture proposée doit préserver un accès aux données les plus récentes même en cas de rupture télématique. En effet, les données médicales revêtent un caractère crucial pour la santé des patients, notamment dans les services d’urgence et de soins intensifs.

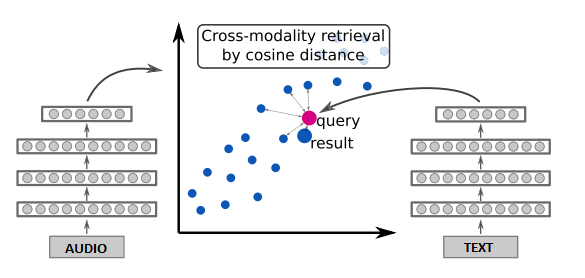
Système de récupération d’audios à partir d’une recherche textuelle.
Travail réalisé par Anissa FATTAHI – 2019
Dans ce projet de fin d’études, je cherche à déterminer si la récupération de sons à partir d’un paragraphe de texte est possible. Je ne considère pas les sons de type musique ou langage parlé. Une des utilisations finales serait de pouvoir générer automatiquement des bandes-son pour des livres.
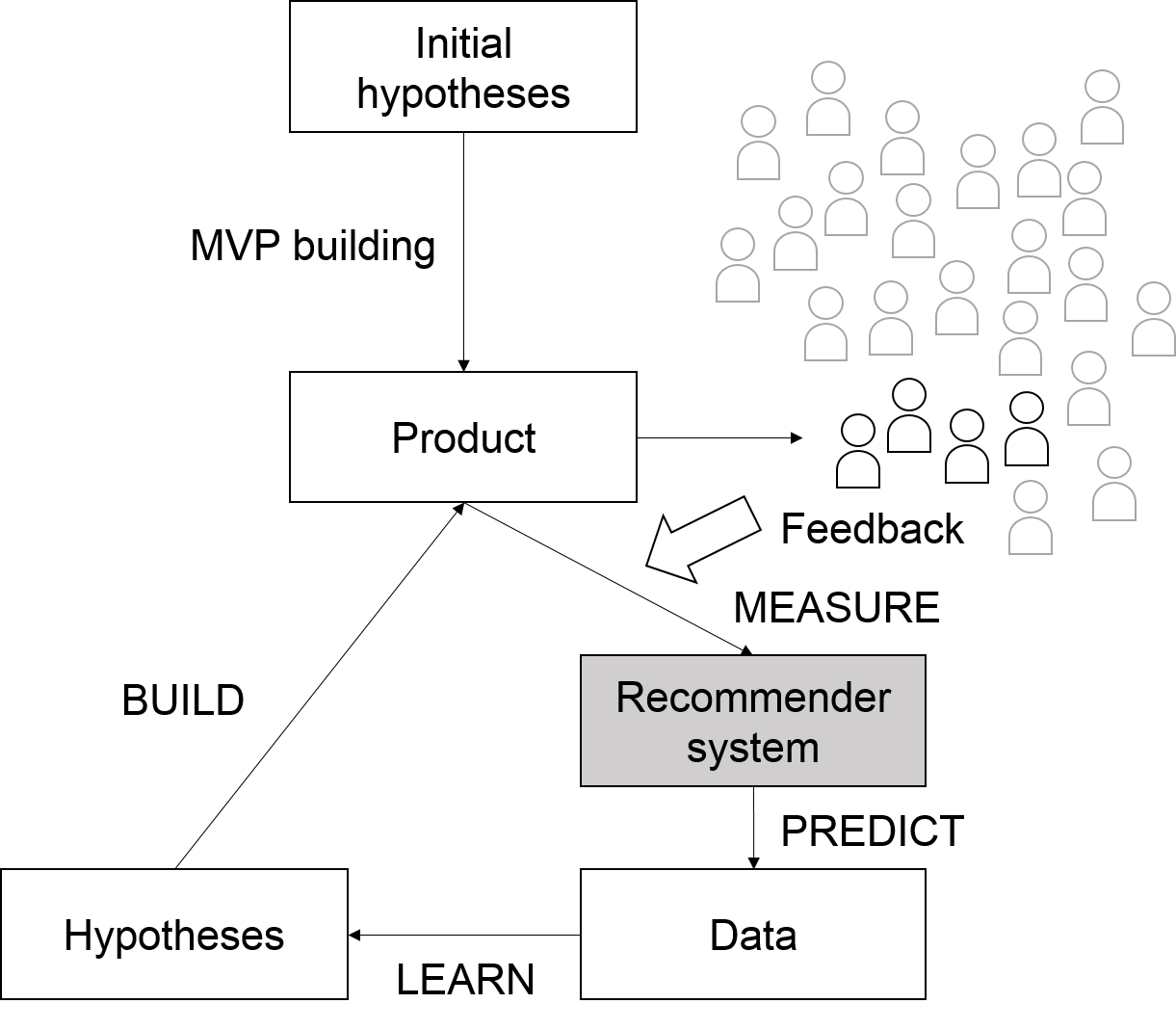
Recommendation Techniques for Predicting Market Responses to New Products or Features
Work done by Santo RANERI – 2019
Imagine that you are willing to create a new product. You probably already know that spending months to build the perfect product before releasing it is not an effective way to operate. You probably heard about agile methods and Lean Startup? The Lean Startup methodology calls for establishing hypotheses to integrate in a simple version of the product (the Minimum Viable Product) in order to collect feedback from customers through the Build-Measure-Learn loop. But what if you want to assess what more people think about your MVP? The new Build-Measure-Predict-Learn loop presented in this figure aims to predict what people in gray are likely to think about the new product while the classic loop only pays attention to people in black. People in gray are those for which we know opinions to previous products or previous versions of the product.
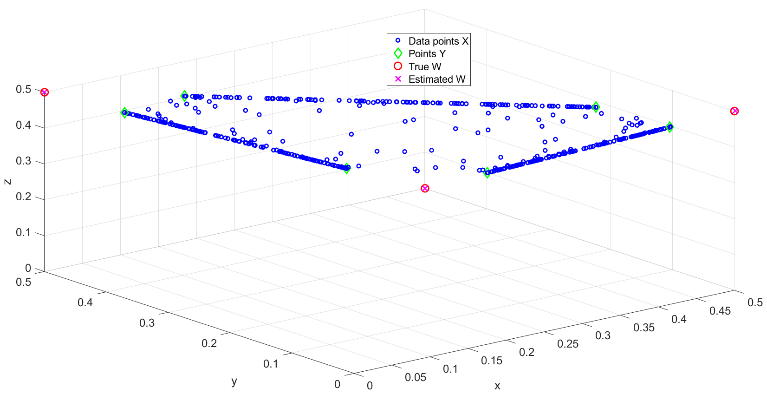
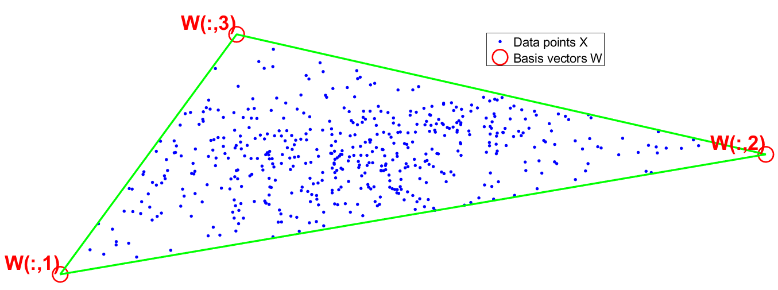
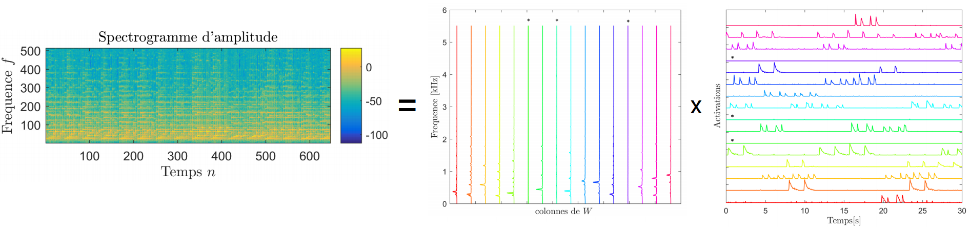
Factorisation non-négative et « presque convexe » de matrices
Travail réalisé par : Pierre De Handschutter – 2019
La factorisation non-négative de matrices (NMF) est une technique linéaire de réduction de la dimensionnalité dans des bases de données de grande envergure (« Big Data »). Les données, contenues dans une matrice X, sont approximées par des combinaisons convexes de r vecteurs de base wi, où r est le rang :
X:,j = w:,1h1j + w:,2h2j + … + w:,rhrj .
L’analyse par archétypes (AA) est une variante de la NMF où les vecteurs de base wi (aussi appelés archétypes) doivent eux-mêmes être combinaisons convexes des données X:,j. Bien que plus interprétable que la NMF classique, AA produit généralement une erreur de reconstruction plus grande, due à ces contraintes supplémentaires.
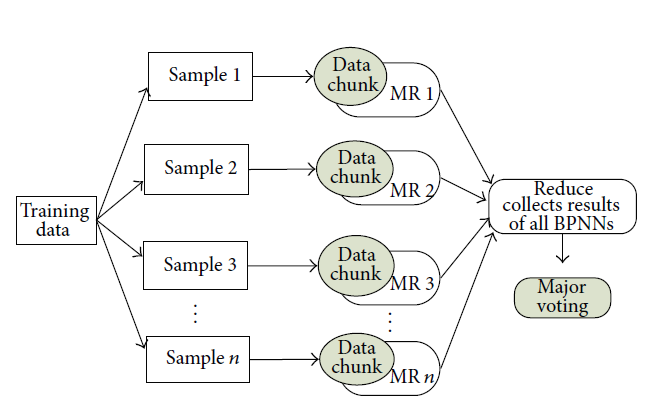
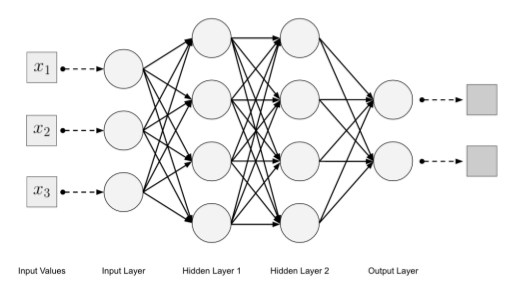
Ensemble-based MapReduce Convolutional Neural Network
Travail réalisé par : Gauthier DEROUX – 2019
In this work, we experiment our algorithm by training multiple CNN on two different images classification problem. The approach is implemented using TensorFlow, Hadoop and Docker. In order to make sure that the algorithm is generalizable to multiple models, we have implemented two different CNN. The results are displayed in terms of speedup and accuracy and is compared to other MapReduce approaches.

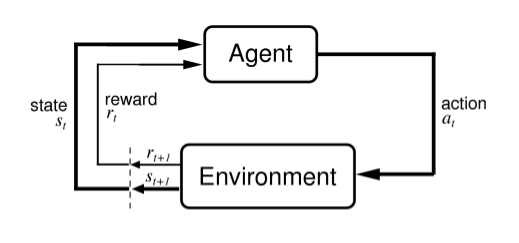
Active Learning in Recommender System
Travail réalisé par : Tristan Germy – 2019
This work has for ambition to highlight the interest of active learning in recommender system applications. In order to restrict the environment associated to my thesis, I have chosen to work on collaborative filtering recommender system because it is the most popular one and it is also very easy to implement. Regarding to active learning, I have chosen to use non-interactive algorithms based on mathematical models. My approach was to avoid the acquisition of new points.
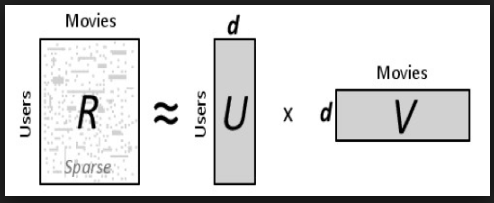
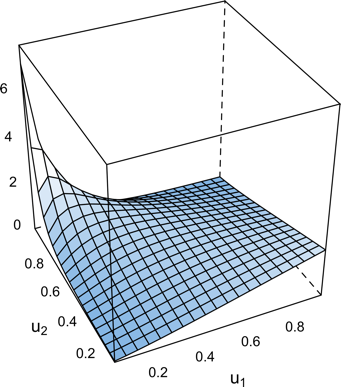
Copulae techniques: Applications for data pre-processing and data analysis phases of the data mining process
Travail réalisé par : Maxime Manderlier – 2019
Data mining is composed of pre-processing and analysis phases. The pre-processing step especially includes handling missing values and dimensionality reduction. The analysis phase is dependent on the task to perform and can be for example clustering, forecasting or classification. In this work, our interest is on the classification task.
Probability theory should be considered to solve these problematics. Copula theory allows to describe the dependence structure of a dataset by the help of the joint distribution. The first step of our work is to correctly describe the joint distribution of a dataset in the purpose of extracting future information from that description. The Vine copula structure is used to model the joint distribution of a dataset.
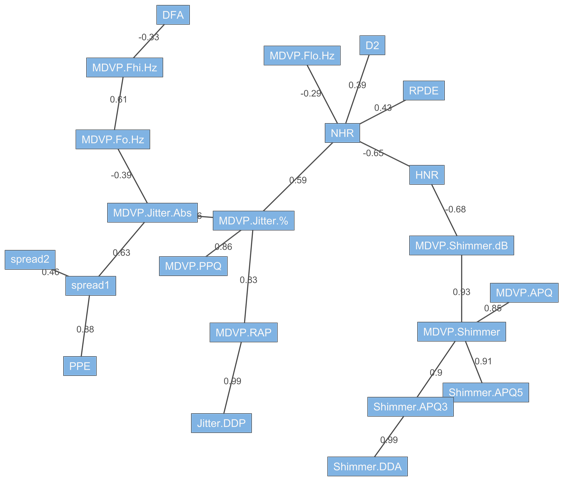

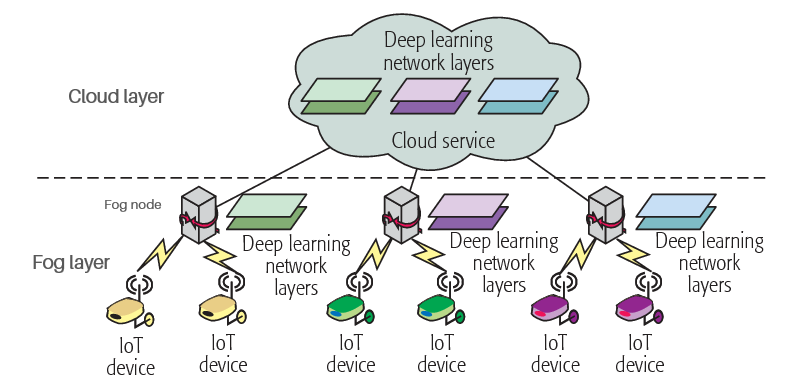
Utiliser le Deep Learning dans une architecture de Fog Computing pour prédire les maintenances d’un procédé industriel
Travail réalisé par : Adelin Rommes – 2019 – Mittuniversitetet, Sundsvall-Suède
Ce travail a été réalisé dans le groupe de recherche du département de Communication System and Technology à Mittuniversitetet - Mid Sweden University à Sundsvall, Suède.
Ce travail d’étude a pour but d’étudier la faisabilité, l’utilité et l’efficacité d’utiliser des algorithmes de Deep Learning dans une architecture de Fog Computing afin de faire des maintenances prédictives d’un procédé industriel.

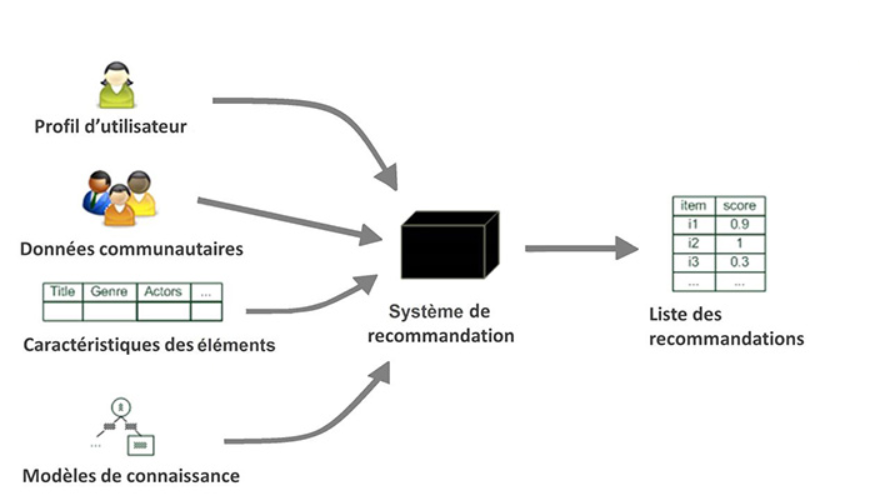
Analyse de l’impact des représentations de l’image sur différentes méthodes de recommandation destinées aux réseaux sociaux
Travail réalisé par : Marco Ricciolini – 2019
Un grand nombre de systèmes de recommandation existent dans divers domaines. Leur objectif est de fournir des suggestions d’éléments qui sont le plus susceptible d’intéresser un utilisateur particulier. Les méthodes généralement utilisées pour le calcul de la recommandation sont soit basées sur le contenu (similarité entre éléments) soit sur la similarité de l’utilisateur avec les autres utilisateurs (filtrage collaboratif) ou bien sont des systèmes hybrides combinant ces deux méthodes.

Optimisation de la capture d'images pour la reconstitution 3D
Travail réalisé par : François Robberts – 2019
Ce travail de fin d’étude porte sur l’étude de l’influence des différents facteurs entrant en compte dans le processus de création d’un nuage dense de points, au moyen de la photogrammétrie terrestre. Souvent choisies au jugé par l’utilisateur, les différentes variables employées lors du processus pourraient être optimisées afin d’économiser du temps de calcul et améliorer la qualité du modèle généré. Les variables étudiées sont le nombre de photographies, les angles de prise de vue, la qualité de la carte de profondeur, la qualité de l’alignement et le choix du filtre.

Apprentissage par renforcement profond pour la résolution de jeux avec OpenAI Gym
Travail réalisé par : Pierre Van Rijmenant – 2019
Ce travail de fin d’étude a pour objet d’implémenter des algorithmes et des méthodes d’apprentissage par renforcement profond pour la résolution de jeux avec OpenAI Gym.
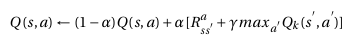
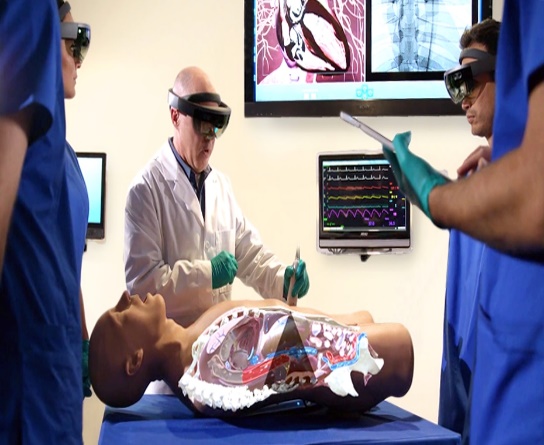
Simulation d’un dialogue patient-docteur avec un mannequin réel possédant un visage virtuel affiché en réalité augmentée
Travail réalisé par : Florian Gielen – 2019
En s’inspirant des émotions humaines, le but de mon travail était de rendre un mannequin de simulation médicale plus vivant grâce à la réalité virtuelle. La réalité augmentée est visionnée à l’aide du casque Hololens de Microsoft. Un visage virtuel a donc été créé dans ce but, la reconnaissance vocale permet quant à elle de le faire passer d’une émotion à l’autre.




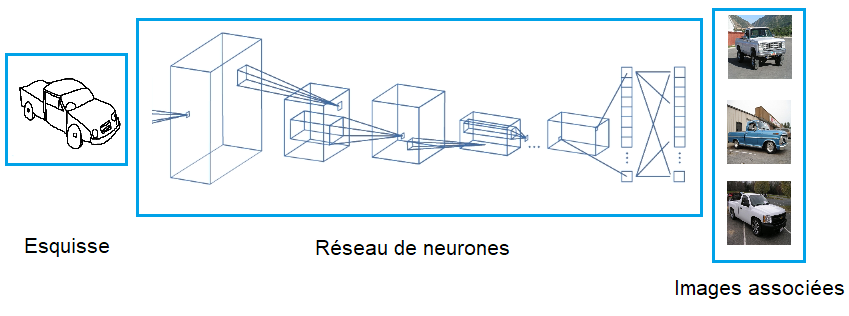
Deep for Sketches : Les réseaux de neurones convolutionnels « CNN » pour la recherche d’images basée sur les esquisses.
Travail réalisé par : Paul Rivière – 2019
Reconnaître les objets présents dans les esquisses et y associer des images est une tâche difficile pour un ordinateur. En effet, l’information contenue dans les esquisses est propre à la perception humaine de l’objet.
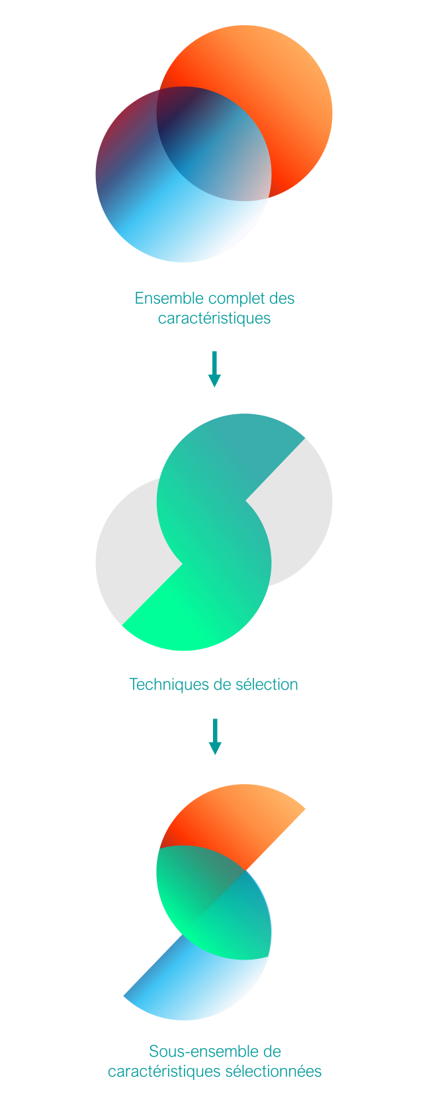
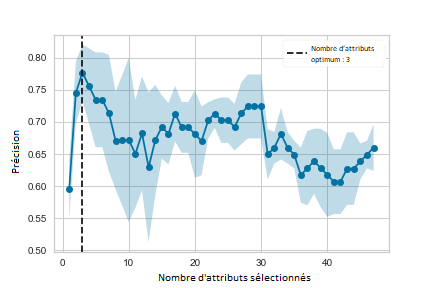
Utilisation de la sélection d’attributs dans l’aide à la décision clinique
Travail réalisé par : Camille Delbrouck – 2019
L’utilisation des méthodes de classification est largement adoptée dans les applications de soins de santé, pour appuyer les décisions de diagnostic médical, améliorer la qualité des soins aux patients, etc. Dans un objectif de meilleure compréhension d’une problématique médicale, un sous-ensemble de caractéristiques peut être sélectionné. Cette sélection permet également de palier la présence de facteurs non pertinents au sein d’un ensemble de données.
Ce mémoire propose une approche de sélection de caractéristiques complémentarisant la recherche médicale et permettant l’aide à la découverte par le corps médical de nouveaux facteurs déterminants dans la prédiction d’une issue clinique.